A day in the life of a data engineer
Data engineers build the foundation the whole company runs on: the pipelines, schemas, and tests every analyst and model depend on. It's real software engineering with real ownership. Here's what the day looks like.
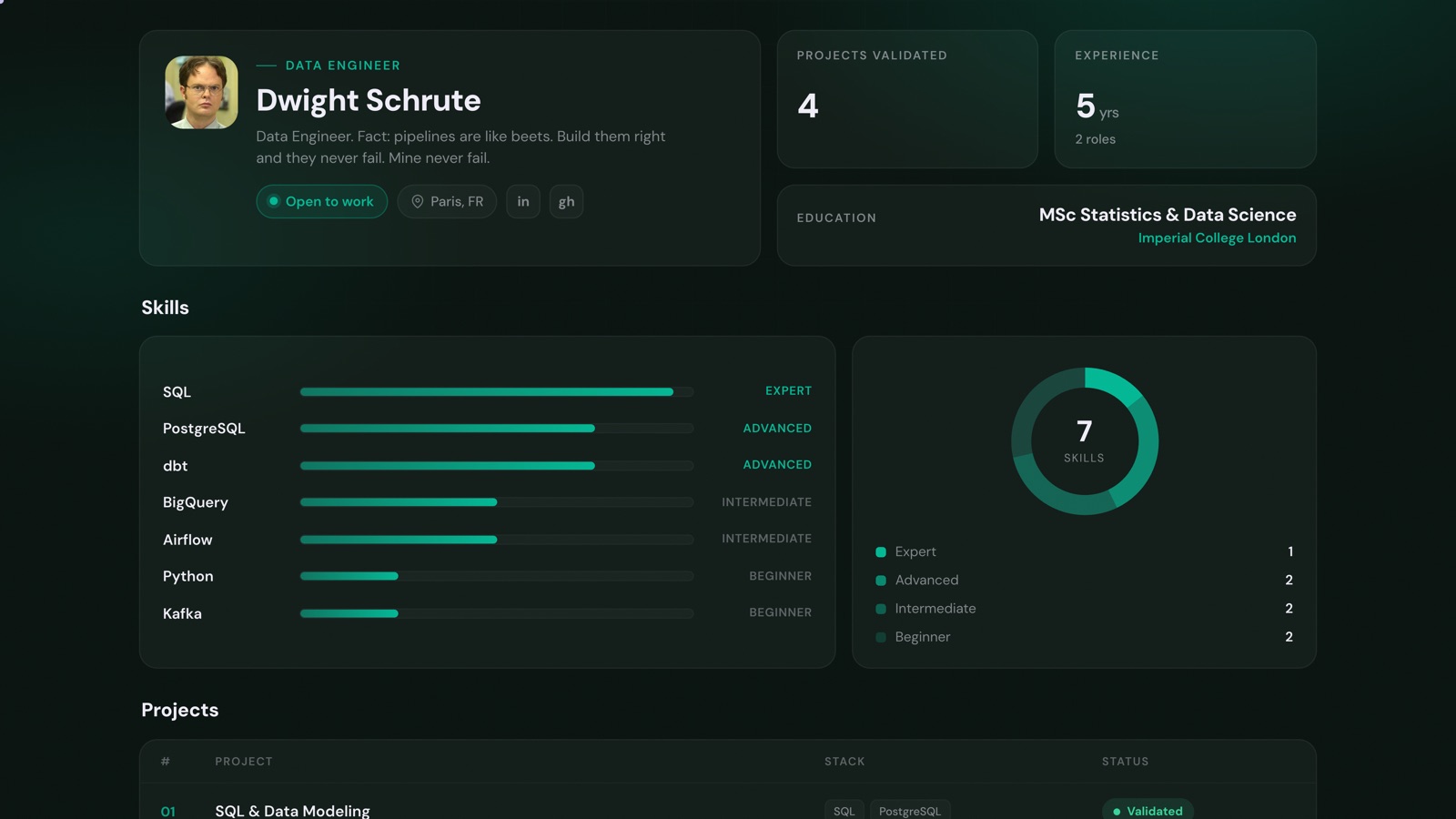
Data engineers build the foundation everyone else stands on. The pipelines, schemas, and tests you create are what let every analyst and every model trust the numbers they see. It's real software engineering, with real ownership, and a deep satisfaction in building systems that just work.
To keep this concrete, we'll follow one engineer through his day: Dwight Schrute. The day is a composite, but Dwight is real enough to click on. His D8A portfolio is public, and every project he points to at the end is validated work you can open and inspect.
Builds the pipelines everyone else depends on, and the tests that let them sleep.
“Data Engineer. Fact: pipelines are like beets. Build them right and they never fail. Mine never fail.”
Open Dwight's portfolio →What does a data engineer actually do all day?
Analysts and scientists get the data; someone has to make sure it arrives, on time, correct, and in a shape anyone can use. That someone is the data engineer. The core activity is always the same: moving and transforming data reliably, so that the people downstream never have to think about where it came from.
Some days that means designing a new pipeline from scratch. Other days it means hardening an existing one so it never wakes anyone at 3am again. Here is what a typical day looks like.
The DE day at a glance
A typical day, with Dwight
Dwight is a mid-level data engineer on a platform team at a mid-sized company. The timestamps don't matter; the rhythm does.
- 8:30
Did everything run overnight?
First thing, before coffee: did the overnight jobs succeed? Dwight scans the orchestrator. Most ran green. One failed a data-quality test, which means it stopped on purpose rather than shipping bad numbers into a dashboard. He considers this a feature, and is correct.
- 9:00
The upstream that changed a field
The failed job traces back to a product team that renamed a column without warning. Dwight's pipeline caught it instead of silently corrupting a week of reports. He patches the schema, backfills the gap, and adds a check so this exact surprise can never pass quietly again.
- 10:00
Fifteen minutes, no heroics
The team syncs. Dwight reports the caught failure, the fix, and flags that the upstream team needs a contract: data shouldn't be allowed to change shape without notice. Boundaries, formally enforced. He has Opinions about people who skip tests, and shares exactly one of them.
- 10:30
Designing a schema that will last
A new analytics use case needs a new table. Dwight designs the model carefully: grain, keys, naming, and how it will behave when volume grows tenfold. A schema is a promise to everyone downstream, and changing it later is expensive. Measure twice.
- 12:00
Lunch (eaten with suspicion)
Dwight takes a break, mostly so he can return sharper to the part of the day where a wrong decision is hard to undo. He does not trust the office microwave and he is not wrong about that either.
- 13:00
Building the dbt models and their tests
Dwight writes the transformation layer: raw data into clean, documented, tested tables. The tests matter as much as the logic. A transformation without a test is a rumor. Each model ships with assertions about what must always be true.
- 14:30
Wiring it into the schedule
The new pipeline gets added to the orchestrator: dependencies declared, retries configured, alerts pointed at the right channel. Dwight is careful about ordering, because a job that runs before its inputs are ready is a quiet way to ship yesterday's data as today's.
- 15:45
The real-time path
One product feature can't wait for the nightly batch, so part of the data flows through a streaming pipeline. Dwight checks lag, handles a malformed message gracefully instead of letting it crash the consumer, and confirms the real-time and batch numbers reconcile.
- 16:45
Documentation and a calmer tomorrow
Dwight documents the new tables and the contract with the upstream team, and tightens an alert that was too noisy to be useful. The goal of a good data engineer is a boring on-call rotation. Boring is the highest compliment a pipeline can earn.
- 17:30
Green board, clear head
A last look at the orchestrator: all green, alerts sane, nothing waiting to ambush the night shift. Dwight ends the day with a quiet system, which is the entire point of the role.
When the data just works, every analyst and every model in the company moves faster without even thinking about it. That quiet, invisible leverage is the whole point of the craft.
From the day to the portfolio
Here's the catch: when data engineering is done perfectly, nothing dramatic happens and the work stays invisible. So how do you prove it? You build artifacts. Every thread of Dwight's day maps onto a concrete, validated project on his portfolio:
SQL & Data Modeling
The schema work from 10:30, where a durable table design becomes a promise the whole company can build on.
dbt Transformation
The tested transformation layer from the afternoon, where raw data becomes clean, documented, trustworthy tables.
Airflow Pipelines
The orchestrated jobs that ran (or correctly refused to run) overnight, with dependencies and retries done right.
Streaming with Kafka
The real-time path feeding the product feature that can't wait for the nightly batch.
This is the difference between saying you can do the work and showing it. Dwight's day is a story; his portfolio is the proof.
What a DE uses every day
The tools vary by company, but the categories are consistent.
SQL
The foundation: modeling, transforming, and validating data.
Python
Glue, custom logic, and anything the SQL can't reach.
dbt
Transformations, tests, and documentation as code.
Airflow / Dagster
Orchestration: what runs, when, and in what order.
Kafka
Streaming and real-time data movement.
Spark
Heavy transformations over large volumes.
BigQuery / Snowflake
The warehouse the whole company queries.
Docker / Terraform
Reproducible environments and infrastructure as code.
Git / CI
Versioning and testing pipelines like the software they are.
The good and the hard parts of the job
- You build foundations the entire company depends on
- It's real software engineering, with real craft and rigor
- Strong, durable demand and excellent compensation
- Clear sense of ownership: the pipeline is yours, end to end
- Problems are concrete and satisfying to solve well
- When it's built right, it just works, quietly, for years
- Success is invisible; failure is very visible and often at 3am
- On-call and upstream changes you don't control can ruin a day
- A lot of unglamorous reliability work nobody sees
- Bad early schema decisions are painful and expensive to undo
- You're downstream of everyone's mess and upstream of everyone's trust
- Easy to be taken for granted until the day it all breaks
Who thrives as a data engineer
The DE role suits people who like building robust systems, take quiet pride in reliability, and would rather prevent a fire than be praised for fighting one. You need genuine engineering discipline, but the rarer trait is conscientiousness: caring that the data is correct even when nobody is checking.
If you're the person who, handed a script that "usually works," immediately asks "but what happens when the input is empty?" then you might already be thinking like a data engineer.
The underrated advantage: domain knowledge tells you which data actually matters. An engineer who understands the business knows which pipeline failing is a minor annoyance and which one stops the company, and prioritizes accordingly.
Explore all data careers at D8A Academy
Whether you are exploring a career change or just trying to understand which role fits you, D8A has a guided, project-based track for each of the four data paths: Data Analyst, Data Scientist, Data Engineer, and Business Analyst. The fastest way to find out whether a role is right for you is to build something in it.